Netflix used to have a lot of different models for different tasks like search, home feed, recommendation sidebar, etc.
specially in the homepage, you have two rank items two ways. vertically and horizontally. different models were used for both.
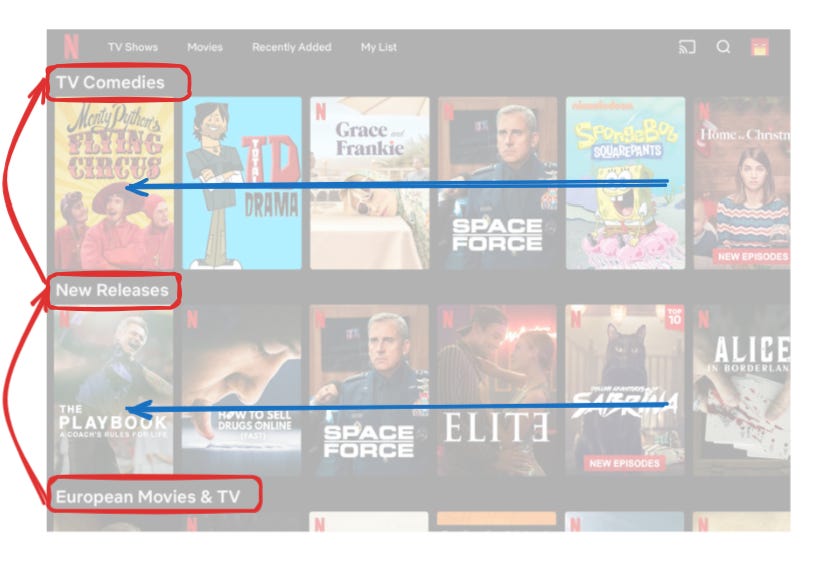
so Netflix has to rank TV-Comedies , New Releases and European section vertically and rank individual movies within these sections horizontally.
so Netflix said fuck it, lets use a single transformer model for all these different task
we will be covering two topics
Foundational Model (FM) Architecture
How it is Served —> because the FM is computationally expensive and slow, we almost never use it as it as, we club it with smaller models and use it.
Foundational Model Architecture
the architecture is more or less similar to a transformer architecture. with two major differences
Tokens and Tokenizer
Loss Calculation
Tokens and Tokenizer
unlike llms where tokens are numbers converted from words. here tokens are Events
This is how one Token/Event looks like
{
"timestamp": 1721289600,
"what": {
"action_type": "play",
"entity_id": 80057281,
"entity_type": "show",
"duration_watched_seconds": 1800
},
"where": {
"device": "TV",
"canvas": "home_page_row_3",
"locale": "en-US"
}
}
you pass a history of tokens like these to the FM same as we do with llms
but how to make embedding out of this token?
so we have embedding look up tables for each key, for example we would have an embedding table for action_type
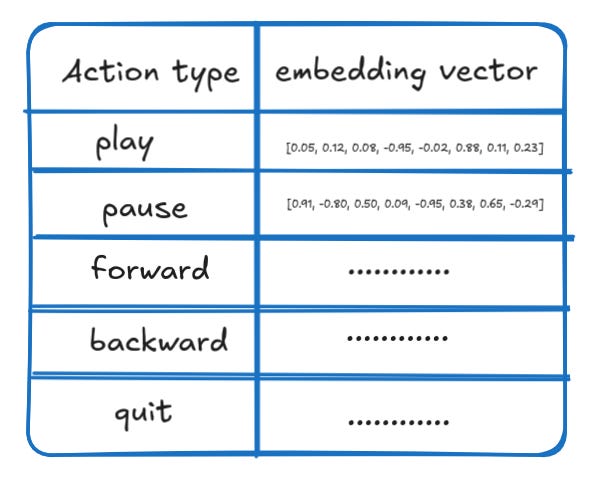
initially these embedding vectors are initialized randomly and later trained via backprop.
now all the embedding vector of different keys (action_type, entity_id , etc) are concatenated into one single vector by adding them vertically and then passing through a linear layer.
this is how we get our embedding vector.
Loss Calculation
unlike a standard transformer llm where we only have a single output head here we have output heads equal to the number of keys in the tokens.
there would be an output head which will only predict the next action type, similarly there would be an output head which would predict the entity type.
total loss = sum of losses from individual output heads and then we train out parameters via backproping on this total loss.
this ensures that every key params learns from loss of every other key too.
How FM is Served
Pattern 1: Subgraph Integration
basically you want to train a smaller model for a specific task suppose, home feed slot ranking ( TV Comedies > New Releases > Animated movies)
so you take some initial layers of FM whose weights are frozen and attach some linear layers above that who are trainable.
and then you train this model on some training data, because of the frozen FM layers you get all the context of user which was trained on much larger data
Pattern 2: Embedding Store
you run the FM, and for every user in your database and every movie/show/item. you generate their vector embedding (because these were trained parameters, these contain meaning).
and store them into key(user or item) - value(embedding vector) pairs.
so when a user is using Netflix , you first select the top 1000 movies/shows to watch using standard algorithms like collaborative filtering. then the task is to rank them for the user.
so you take the embedding vectors of users and these 1000 items , do dot product on them and rank according to the dot product score.