These are working notes on distributed training: communication collectives, data parallelism, tensor parallelism, FSDP, sequence parallelism, and pipeline parallelism.
intranode communication is faster than internode communication
Basic Operations
Broadcast: GPU 0 starts with the data (e.g., model weights) and sends a copy to GPU 1, 2, and 3 so that all GPUs end up with identical data.
Scatter: GPU 0 starts with a list of data items [A, B, C, D], splits it into chunks, keeps A, sends B to GPU 1, C to GPU 2, and D to GPU 3, so the data is partitioned and each GPU owns a slice.
Gather: Each GPU has a partial result (GPU 0: A, GPU 1: B, GPU 2: C, GPU 3: D), everyone sends their piece to GPU 0, and GPU 0 ends up with the full list [A, B, C, D] while others still only have their own piece.
All-Gather: Each GPU starts with a piece (A, B, C, or D), everyone sends their piece to everyone else, and every GPU ends up with the full list [A, B, C, D], but this is expensive because it moves a lot of data.
Reduce: Each GPU starts with a number (GPU 0: 1, GPU 1: 2, GPU 2: 3, GPU 3: 4), everyone sends their number to GPU 0, GPU 0 applies an operation like sum to get 1+2+3+4=10, so GPU 0 holds the reduced result (10) while others keep their original numbers.
its basically a gather operation at the end of which a sum or avg or max happens, but then why it is given a separate name, no clear answers but yeah the sum happening at the end can be made very efficient if we know we are gonna sum
All-Reduce: basically suppose you have vectors of size 4 in 4 saperate gpu’s
gpu 1 —> A0 A1 A2 A3 gpu 2 —> B0 B1 B2 B3
gpu 3 —> c0 c1 c2 c3 gpu 4 —> d0 d1 d2 d3
now you want each gpu to have four elements [sigma a , sigma b, sigma c, sigma d] what you will do , you will perform an internal reduction in each gpu and then perform an all gather right
but what if you have
gpu 1 —> A0 B0 C0 D0 gpu 2 —> A1 B1 C1 D1
gpu 3 —> A2 B2 C2 D2
gpu 4 —> A3 B3 C3 D3
and you want each gpu to have four elements [sigma a , sigma b, sigma c, sigma d]
one approach you can take is gpu 1 sends b0 c0 d0, and receives a1 similarly for all other gpus, but this approach is kind of inefficient. because every node is talking to every node, congesting the network
alternate approach :- Ring Reduce
Initial State (Time = 0):
GPU 0: [A0, B0, C0, D0] GPU 1: [A1, B1, C1, D1] GPU 2: [A2, B2, C2, D2] GPU 3: [A3, B3, C3, D3]
Step 1 of 3:
GPU 0: [A0, B0, C0+C3, D0] GPU 1: [A1, B1, C1, D1+D0] GPU 2: [A2+A1, B2, C2, D2] GPU 3: [A3, B3+B2, C3, D3]
Step 2 of 3:
GPU 0: [A0, B0+B3+B2, C0+C3, D0] GPU 1: [A1, B1, C1+C0+C3, D1+D0] GPU 2: [A2+A1, B2, C2, D2+D1+D0] GPU 3: [A3+A2+A1, B3+B2, C3, D3]
Step 3 of 3 (final step of Phase 1):
Send: GPU 0 sends B0+B3+B2 to GPU 1. GPU 1 sends C1+C0+C3 to GPU 2. GPU 2 sends D2+D1+D0 to GPU 3. GPU 3 sends A3+A2+A1 to GPU 0.
Receive and add: GPU 0 receives A3+A2+A1 and adds it to A0. Result: A_sum. GPU 1 receives B0+B3+B2 and adds it to B1. Result: B_sum. GPU 2 receives C1+C0+C3 and adds it to C2. Result: C_sum. GPU 3 receives D2+D1+D0 and adds it to D3. Result: D_sum.
End of Phase 1: Reduce-Scatter is complete.
GPU 0 now holds only A_sum. GPU 1 now holds only B_sum. GPU 2 now holds only C_sum. GPU 3 now holds only D_sum.
The other chunks can be discarded.
or we can now perform an all gather so that everyone has all the sums we call this Ring Reduce All
Memory
Static memory has three parts: weights, gradients, and optimizer states.
With mixed precision (BF16 weights, Adam in FP32), you pay about 16 bytes per parameter:
2 bytes: weights (BF16)
2 bytes: gradients (BF16)
12 bytes: Adam (FP32 master weights + momentum + variance)
For a 7B model, that is roughly 112 GB, even though the raw weights are only about 14 GB.
Dynamic memory comes from activations saved for backprop.
Activation memory scales with sequence length, batch size, hidden size, and number of layers.
activation-memory = s⋅b⋅h⋅(constant)
Activation Checkpointing
A standard Transformer block (simplified) looks like this:
Input (x0) -> [LayerNorm 1] -> (x1) -> [Self-Attention] -> (x2) -> [Residual Add: x0+x2] -> (x3) -> [LayerNorm 2] -> (x4) -> [MLP] -> (x5) -> [Residual Add: x3+x5] -> Output (x6)
we only store x0 and x6 and discard all of them and re-calculate while back propagating to save memory
note : this is only for training we do not do this in infrence, I mean like we cache kv, everything else we anyway delete
Data Parallelism
Split batch: 32 images → 8 per GPU (GPUs 0–3).
Forward: Each GPU runs forward pass on its 8 images with its local copy of the model.
Backward: Each GPU computes gradients from its own 8 images (gradients differ across GPUs).
All-Reduce: Use All-Reduce on gradients to average them across GPUs so every GPU has the same Grad_avg.
Optimizer step: Each GPU updates its local weights with the same rule: Wnew=Wold−lr×GradavgWnew=Wold−lr×Gradavg, keeping all model replicas in sync.
Data Parallel (DDP) assumes each GPU can store a full copy of the model, its gradients, and optimizer states.
For big LLMs, static training memory is huge: a 7B model can need ~112 GB (weights + gradients + Adam states).
With DDP, every GPU must hold this full 112 GB copy.
Even if you have 4×80GB GPUs, each individual GPU still can’t fit 112 GB, so DDP will run out of memory and crash.uu
ZeRO Stage 2
why stage two? because stage one is stupid and not worth studying. consider this particular setup
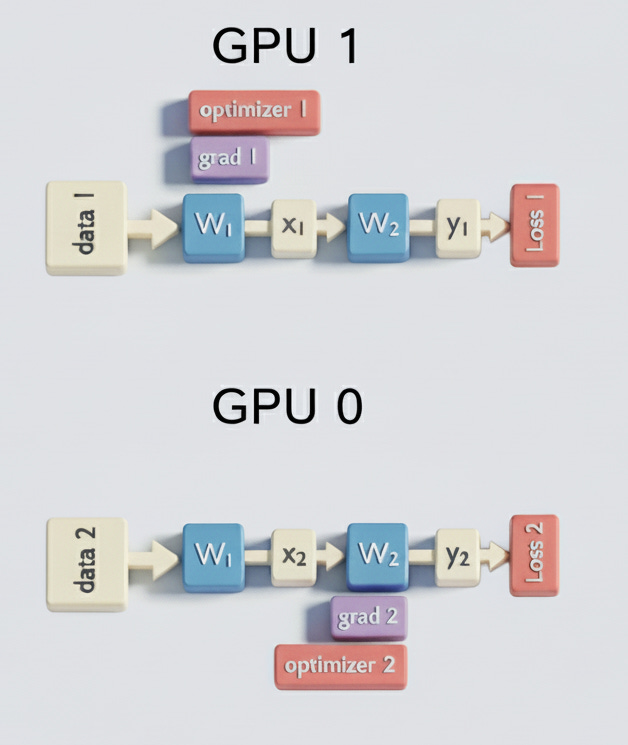
this is a two layer neural net being trained on two saperate gpu’s.
now notice that gradient 2 and optimizer 2 is missing from GPU 1 and viceversa. why? to save space, but then how will we train this?
look at the backward pass, GPU 1 —> we calculate gradients for W1 and W2 both GPU 0 —> we calculate the gradients for W1 and W2 both
now we do ring-reduce-scatter and GPU 1 has the average gradient for W1 and GPU 0 has average gradient for W2 (all other gradients are deleted, for example GPU1 deleted gradient for W2) , they individually update the weights with the optimzers they have and then share the weights (GPU 1 shared W1 and GPU0 shares W2) through an all gather.
basically as soon as gradients for W2 are calculated, an all reduce takes place, the weights are updates for W2 on a specefic gpu and then all the gradients for W2 accross all gpus are thrown away
instead of storing all the gradients for all the weights, we need to store them for only a single layer at a time
what if we are training lamma 70b, its weights require 140GB but we do not have that in a single GPU so we will have to distribute the weights too, but how will we do that
Stage-3 / FSDP
the forward pass starts at layer i. the weights for layer i are split into pieces, with each gpu holding one piece. at this point, no gpu can do any calculation because each only has part of the weights.
the system then does an all-gather operation on the weights. each gpu sends its piece to all others. for a short time, every gpu has the complete set of weights in memory.
now, each gpu runs the forward pass using the full weights to compute the output.
as soon as the calculation is done, each gpu deletes the full weights from memory. they only keep their original small piece. this brings memory usage back down.
later, during the backward pass, the gradients need to be calculated for layer i. to do this, the full weights are needed again, but they were deleted.
so, the system does another all-gather on the weights. each gpu sends its piece again, and every gpu reconstructs the full weights in memory.
each gpu then computes the gradients using the full weights.
after this, the gradients are reduced and scattered. each gpu gets only the part of the gradients that matches its original weight shard.
finally, each gpu deletes the full weights and the full gradient vector from memory, keeping only its own small piece.
weights are stored in FP-32 but converted into fp-16 at the time of transmission and calculation
Tensor Parallelism
lets just say that if we were doing fsdp to save memory then we are doing tensor parallelism to save compute
if you do not know how block matrix multiplication works check it out here
I want you to forget all about data parallelism for now, we are training on a single batch of data
the multi-layer perceptron (mlp) in a transformer is made of two linear layers with an activation function in between. for layer a, the math is y = x * a. the input x has size [1, h], and the weight matrix a has size [h, 4h]. the output y has size [1, 4h].
when using two gpus, the weight matrix a is split along the columns. gpu 0 stores the left half of a, called a_left, and gpu 1 stores the right half, called a_right. both gpus have the full input x. each gpu computes its part: gpu 0 calculates y0 = x * a_left, and gpu 1 calculates y1 = x * a_right. the result y is split between the two gpus, with each holding half.
next, the activation function gelu is applied. since gelu works on each number independently, each gpu applies it to its own part of y. gpu 0 gets y0’ = gelu(y0), and gpu 1 gets y1’ = gelu(y1). no communication is needed, and the output remains split.
for layer b, the math is z = y’ * b. here, y’ is split, with each gpu holding half. the weight matrix b has size [4h, h], and is split along the rows. gpu 0 stores the top half, b_top, and gpu 1 stores the bottom half, b_bottom. each gpu computes a partial result: gpu 0 calculates z_partial_0 = y0’ * b_top, and gpu 1 calculates z_partial_1 = y1’ * b_bottom. both partial results have size [1, h].
to get the final output z, the two partial results must be added together. this is done using all-reduce (sum). both gpus send their partial result to each other, add them up, and now both have the complete output z. after all-reduce, both gpus hold the same final tensor z
This is why Tensor Parallelism is strictly restricted to NVLink (Intra-Node). why? because it is of blocking nature, in the fsdp all-geather we can perform all geather in the background while the computation is going on
how will this work with fsdp weight sharing?
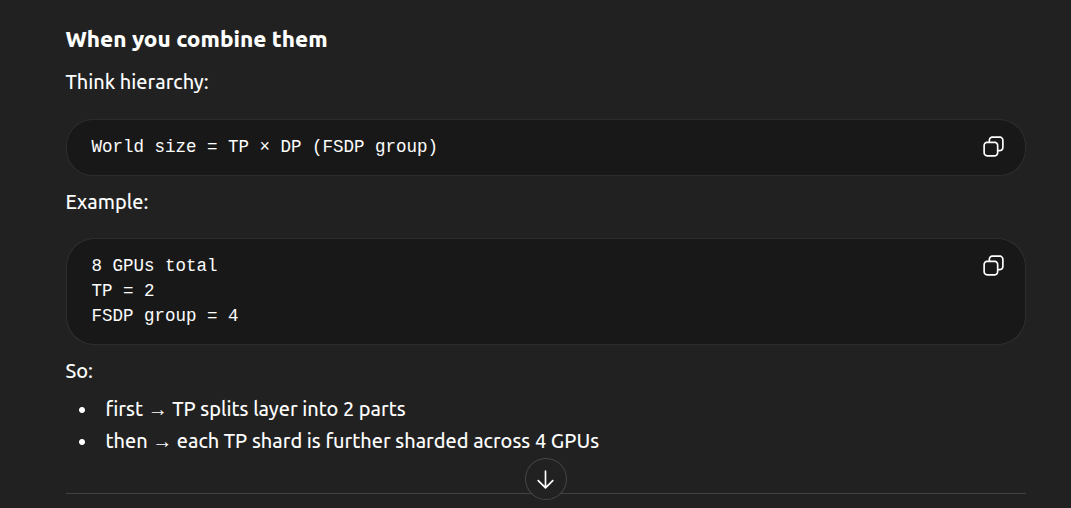
now lets see how we can combine tensor parallism and fsdp
the hardware is set up as a 2d grid: 4 nodes, each with 8 gpus. inside each node, gpus are connected by nvlink (intra-node). nodes are connected by ethernet or infiniband (inter-node). tensor parallelism (tp) runs horizontally (inside a node), and fsdp (data parallelism) runs vertically (across nodes).
a weight matrix w of size is split in two steps. first, tensor parallelism splits w into 8 vertical columns, called wtp0 to wtp7. in pure tp, each gpu in a node would hold one full column. but with fsdp, each column is further split across the 4 nodes. for example, wtp0 is split into 4 pieces: node 1 gpu 0 holds chunk 1, node 2 gpu 0 holds chunk 2, and so on. each gpu ends up with 1/32 of the total weights.
for the forward pass, each gpu must compute its part of the matrix multiply. say node 1 gpu 0 wants to compute ylocal = x * wtp0. but it only has one chunk of wtp0. so, it does an all-gather across the vertical (inter-node) axis: node 1 gpu 0 talks to node 2 gpu 0, node 3 gpu 0, and node 4 gpu 0 to get all chunks of wtp0. now it has the full wtp0 in memory.
next, it computes ylocal = x * wtp0 locally. after this, it must combine results with other gpus in its node. each gpu in node 1 does the same for its own column. then, they do an all-reduce horizontally (intra-node) over nvlink, summing their partial results. now, every gpu in node 1 has the full output z
Sequence Parallelism
The Problem
each gpu holds a full copy of the activation tensor after the row-parallel linear layer, even though only part of the computation is unique before all-reduce.
with sequence length 1,000,000, hidden size 8,192, and bf16, the tensor shape is and takes about 16 gb per gpu.
after all-reduce, every gpu has the same final tensor z_total, so all 8 gpus store identical 16 gb copies. total memory used is 128 gb, but only 16 gb is unique data.
for layernorm and dropout, each gpu processes its own copy of z_total. the work is not parallelized; every gpu does the same math and produces the same result.
this wastes both memory and compute, since all operations are repeated across gpus instead of being distributed or optimized
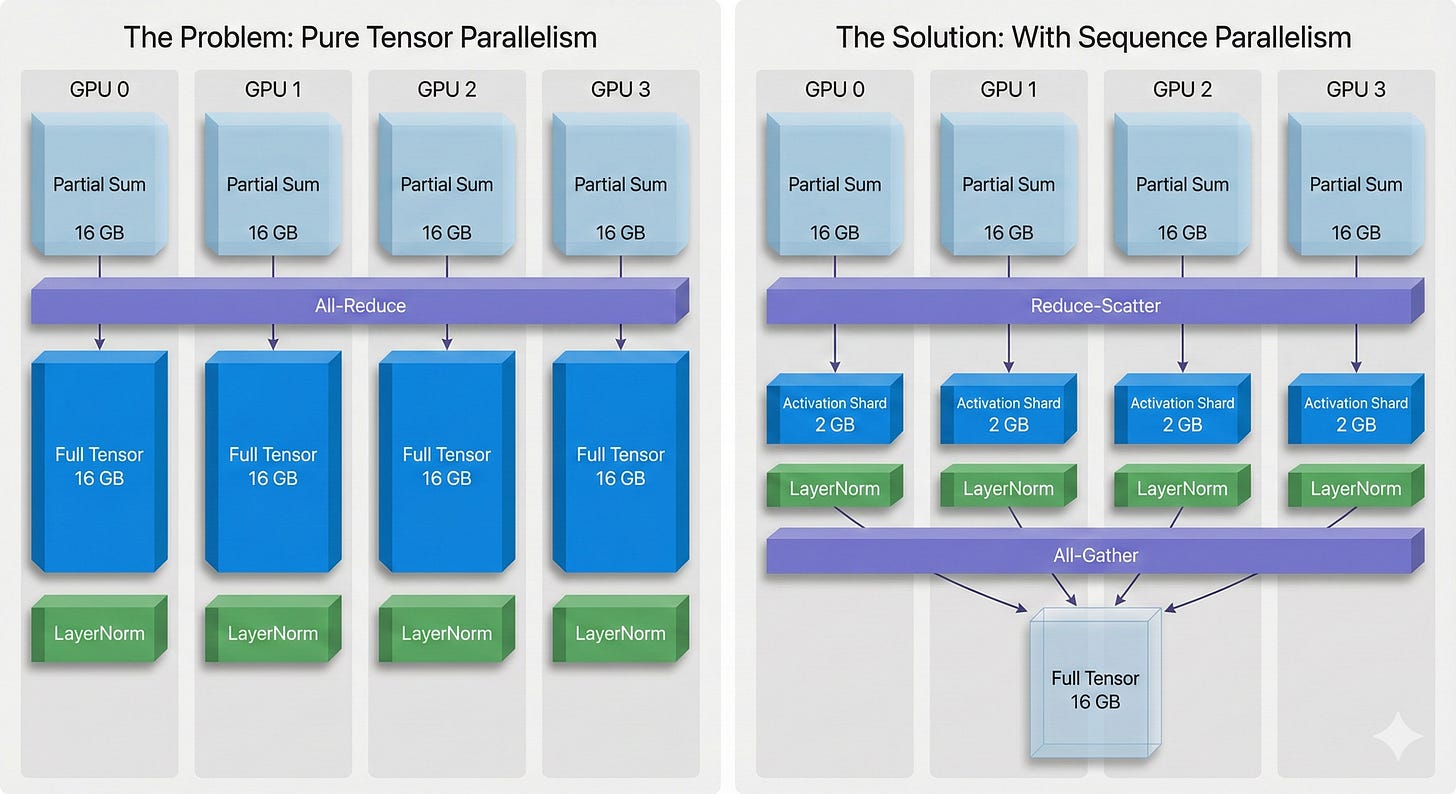
The Solution
at this stage, every gpu has a partial sum tensor of size 16 gb, matching the full sequence length.
to avoid storing 16 gb on every gpu, use reduce-scatter instead of all-reduce. reduce-scatter sums the partials and then splits the result along the sequence dimension, giving each gpu only 1/8th of the tokens. each gpu now holds a correct, fully summed shard of 2 gb.
for layernorm, each gpu processes its own shard of 125,000 tokens. since layernorm acts per token, each gpu can compute its part independently, keeping memory at 2 gb per gpu.
when the next layer needs the full sequence, call all-gather. each gpu sends its shard to all others, temporarily reconstructing the full 16 gb tensor. after the matrix multiply, discard the full tensor and return to sharded state
fsdp does not shard the activations of layernorm so like how tp+sfdp work together sequence parallelism works alone
Pipeline Parallelism
until now what we have been doing is sharding the weights gradients etc within each layer but a single GPU has to calculate all layers.
in pipeline parallel we divide each layer to a single gpu.
and run micro-batches, accumulate their gradients and update after a full batch has been completed. (doing an reduce scatter at each micro-batch would be very in-efficient)
and when you combine all of these it would become 3d parallel.
lets see it by an example, our setup :-
2 Stages: S0, S1 (to keep it minimal).
3 Micro-batches: mb1, mb2, mb3.
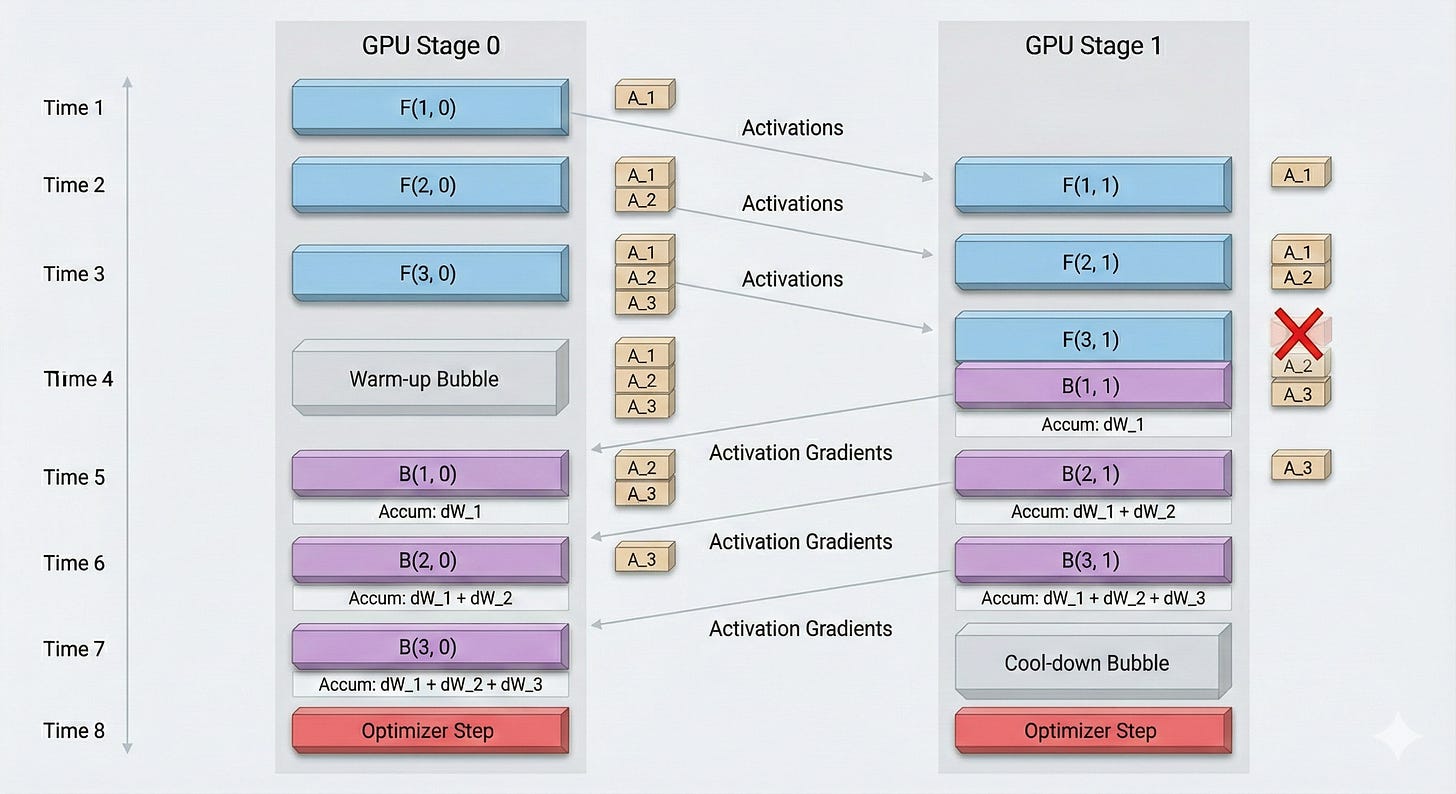
with this you can imagine how all the things we talked about can work together and create a 3d parallel. combining fsdp, tensor parallel, sequence parallel and pipeline parallel